
Creating MaxQuant-compatible mzXML
Published on: Apr 22, 2017 (last update: Dec 18 2019)
The generation of mzXML files which are compatible as input with the MaxQuant software suite allows for several interesting fields of application. In this blog post we will elucidate the challenges of this endeavor and in the end provide several ways to generate MaxQuant-compatible mzXML.
-force_MaxQuant_compatibility in order to create conformant mzXML which can be read by MaxQuant. In some cases, it might have worked without this flag before, but with OpenMS 2.3 it is required.Content
Motivation
MaxQuant is among the most widely used software tools for the processing of LC-MS proteomics data. MaxQuant is originally designed to handle high-resolution MS data of the Orbitrap family from Thermo (Raw file format). Support for other instrument types (high-resolution TOFs) and vendor formats, such as Bruker or AB Sciex has been added over time. These formats however are 'closed', meaning that while there are tools to convert from a vendor format to an open format (such as mzML or mzXML), it's not possible to invert this process.
MaxQuant introduced support for the open XML-based mzXML format around MaxQuant release version 1.2.2.5. This is great, since it allows for a number of use cases:
- Public data repositories (such as PRIDE) may contain projects which only contain the mzML (or mzXML) files which were used as input for open-source tools, such as OpenMS or TPP. This prevents re-analysis using MaxQuant unless you know how to generate mzXML in MaxQuant flavor
- Partially recover broken Raw files by using mzXML converters
- Benchmarking the MaxQuant algorithm with simulated or modified data, which cannot be created in a native vendor format
- Using files from unsupported vendors, which MaxQuant cannot read directly
- Your Thermo Raw files are unavailable (lost), but you still have mz(X)ML files around
- Pre-processing of the Raw data before feeding it into MaxQuant (e.g. custom precursor correction, or to work around MaxQuant bugs; etc.)
All results shown here have been obtained using MaxQuant 1.5.3.12 and have been verified using MaxQuant 1.2.2.5. We presume all MaxQuant versions will behave identically. Reader's input towards either confirmation or falsification is greatly appreciated.
State of the Art
If MaxQuant were to support a standard-conforming mzXML as dictated by the official mzXML schema, this blog post would not be required. As is is, only few reports of successfully running MaxQuant with mzXML input are known. Many users have encountered uninformative error messages when feeding seemingly standard mzXML into MaxQuant (see MaxQuant-Help GoogleGroup).
Even though the source code of the first version of MaxQuant is published (see Suppl. Information of doi:10.1038/nbt.1511), later versions (including the ones which support mzXML) are closed source. This means we cannot simply inspect the source code and 'read out' the mzXML flavor which MaxQuant expects, let alone fix the implementation. Thus, we have to resort to a guided trial and error approach.
Let's look at some conversion programs:
ReAdW
When mzXML capabilities were introduced into MaxQuant a few years ago, ReAdW was among the commonly used file format conversion tools for Thermo Raw to mzXML.
It seems natural to assume that MaxQuant can deal with ReAdW converted mzXML. The original ReAdW 4.3.1 is still available on Sourceforge (but not maintained any longer).
Nevertheless, it does the job just nicely: The number of proteins/peptides are comparable to running MaxQuant on the original Raw file. Well, some information is lost, such as ion injection time and base peak intensity (BPI) as PTXQC would tell you. But these are not of paramount importance. The BPI can even be recomputed from the data.
So why not just use ReAdW? Well, first and foremost: it can convert from Raw to mzXML. Nothing else. This excludes many use cases as mentioned above. But it gives us a nice template of the mzXML flavour which MaxQuant expects. You could also modify/edit the mzXML, which ReAdW produced without risking to break MaxQuant-compatibility immediately, but there is a catch: MaxQuant requires 'indexed' mzXML, which means you have to ensure the integrity of the index (more on that down below).
You might have noticed that there is a ReAdW variant on GitHub, which even runs on Linux/Wine. However, the mzXML is not MaxQuant compatible due to a wrong msManufacturer tag (see below). This ReAdW variant is still maintained however, so depending on your use case, this might be interesting to look at.
To get ReAdW running, you'll need to get your hands on the XCalibur version of the XRawFile2.dll, fileio.dll, fregistry.dll and zlib1.dll, usually to be found in 'C:\Program Files\Thermo\Foundation\*.dll'.
If you do not have XCalibur available, you can also use XRawFile2.dll, fileio.dll, fregistry.dll as shipped with Thermo's MSFileReader. Since you would still be missing zlib1.dll, we simply provide it here for download (zlib.dll) [details (incl. license) of zlib are available at http://zlib.net/].
Once you have grabbed these dlls, you should avoid registering the XRawfile2.dll (using regsvr32.exe) as advertised in some manuals. This might break the registration of XRawFile2.dll of MSFilereader (if installed), which MaxQuant relies upon. The easiest solution is to just copy the dlls into the same directory as ReAdW.exe.
ProteoWizard
The most straight forward approach to generate mzXML from a plethora of vendor formats nowadays is to use ProteoWizard's msconvert, either as graphical user interface (msconvertGUI) or on the command line like this:
// Proteowizaerd's default mzXML: MaxQuant will crash $ msconvert -mzXML *.raw
Using this mzXML, MaxQuant will succeed in the "Testing file(s)" phase, but crash during "Feature Detection" with an error message like this:

Careful investigation and comparison of the ReAdW mzXML and the PWiz mzXML reveals that the latter stores the m/z values in 64-bit precision, whereas ReAdW uses 32-bit.
Note that this has nothing to do with the 'bitness' of your processor (CPU) or operating system. It's simply the precision of the numbers within mzXML.
Proteowizard supports this via msconvert with the flag --32
// this works for .raw (and other formats) -> mzXML // , but the number of peptides/proteins is not optimal $ msconvert --32 --mzXML *.raw
Now, msconvert will create a file about ½ the size and additionally MaxQuant will successfully run through all the way. Unfortunately, the number of identified peptides and proteins will be significantly lower compared to a run using the original Raw file – we will dig into the reasons in a minute.
To summarize, msconvert can take a multitude of different input formats, and generate mzXML which is compatible with MaxQuant (using the --32 flag), but does not give optimal results in terms of number of peptides/proteins.
Getting it right
Re-shaping the mzXML
Note The following section is a bit technical. Some details are certainly only interesting for particular audiences, but I mention them here for completeness. Skip to the next section
OpenMS can create mzXML using it's FileConverter TOPP tool. This only works for open formats like mzML or mzXML (i.e, no native vendor formats), but you already know at least two conversion programs which can get you up to this point. The tricky part is how to generate the right flavour of mzXML.
Even though the mzXML of ProteoWizard and OpenMS passes semantic validation of the mzXML schema, the MaxQuant seems to require a special flavour of mzXML.
Thus we set out using a good share of trial and error to finally determine the exact flavour of mzXML which MaxQuant relies on. We adapted the mzXML implemention of OpenMS, such that it mimicks the ReAdW implementation until MaxQuant successfully read the file and produced results comparable to the original Raw file (our gold standard).
It became apparent rather quickly that MaxQuant requires 32-bit m/z and intensity arrays and one should avoid the tag <msResolution> altogether.
Another obstacle which took a while to unravel was MaxQuant requiring explicit line breaks in XML tags, i.e. this:
<peaks precision="32" byteOrder="network" contentType="m/z-int" compressionType="none" compressedLen="0" >Q5YAOQAAAAB....AAAAA==</peaks>
will crash MaxQuant
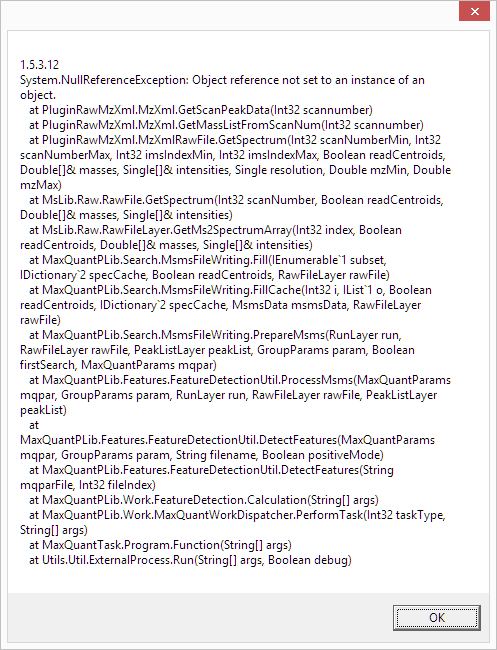
whereas this:
<peaks precision="32" byteOrder="network" contentType="m/z-int" compressionType="none" compressedLen="0" >Q5YAOQAAAAB...AAAAA==</peaks>
is ok (which is how ReAdW and ProteoWizard are doing it -- luckily). The reasons for this behaviour on MaxQuants part can only be answered by its developers.
Then we found that MaxQuant requires indexed mzXML, meaning that at the end of the mzXML file there is a lookup table, which provides byte offsets into individual MS(/MS) scans. If this index is missing, MaxQuant will spend hours torturing your disk (even an SSD!) and is not guaruanteed to complete even the "Testing files" stage -- after having read TerraBytes of data. Since the mzXML needs to be indexed, you cannot simply edit an mzXML file manually, since this will shift the byte offsets, and hence invalidate the index - and guess what happens then: right, MaxQuant will crash.
Getting the Manufacturer Right
Apparently, even if you have correct MS data (32-bit and all, see above) and an index, but get the "meta data" wrong, MaxQuant will produce different results compared to the .Raw file or the ReAdW mzXML, which can be as much as 25/75% less proteins/peptides, respectively - as it happens with ProteoWizard, but not with ReAdW.
So what makes ReAdW 4.3.1 successful? ReAdW writes <msManufacturer category="msManufacturer" value="Thermo Finnigan" /> into the mzXML and this somehow leads MaxQuant to assume ITMS as MS/MS analyzer (see MSMSScans.txt of MaxQuant output). Any other value than "Thermo Finnigan" leads to "Unknown" MS/MS mass analyzer in MSMSScans.txt. This should not have any implications since MaxQuant's MS/MS settings of ITMS and Unknown are identical. Nevertheless, also the MS1 tolerance settings seem to be affected by the msManufacturer. What MaxQuant assumes as default manufacturer (and hence MS1 analyzer) is not clear. It could be any of the other manufacturers, or just some generic default. So we tried: changing the settings for all other manufacturer tabs in MaxQuant (Bruker/Agilent/AB Sciex) to match the Orbitrap defaults, the number of peptides was still way too low. So MaxQuant seems to use some internal defaults for MS1 which cannot be modified by the user. And even if MaxQuant would default to another manufacturer, the manufacturer settings are not permanently changed or saved anywhere, which means you'd have to fix them anew at every startup. So we could simply use 'Thermo Finnigan' as Manufacturer and avoid the whole hassle, right? But we're not quite there yet: testing with MaxQuant 1.2 showed deteriorated results, whereas MaxQuant 1.5 seemed happy. Is 'Thermo Finnigan' a MaxQuant 1.5 thing then, and 1.2 needs another manufacturer? Searching for "F.i.n.n.i.g.a.n" in the MaxQuant 1.5 binaries yields a hit in PluginRawMzXML.dll. Close by, there is another term "Thermo Scientific", followed by the strings ITMS and FTMS. The terms "Bruker" or "Sciex" do not appear. This might indicate that mzXML files can only be dealt with properly if they are truly from Thermo instuments with Orbitrap MS1 and IonTrap MS2. And indeed, using "Thermo Scientific" as msManufacturer yields results which match the Raw file results. Also, "ITMS" is inferred by MaxQuant as MS/MS mass analyzer. MaxQuant 1.2 only understands "Thermo Scientific", not "Thermo Finnigan". MaxQuant 1.3 and upwards understand both terms. Thus, we use "Thermo Scientific" as msManufacturer in our mzXMLs which is compatible with all MaxQuant versions which support mzXML (1.2 to 1.5).
The adapted OpenMS FileConverter speaks MaxQuant-mzXML and is available in the current development version of OpenMS (Windows installer here) as well as any downstream OpenMS release (starting with OpenMS 2.2 in May 2017).
when running any OpenMS tools, simply download sqlite3.dll from here and copy it manually into the OpenMS-head/bin installation folder next to all the OpenMS executables.
This means that you can simply use FileConverter shipped with OpenMS to convert any open format (mzML, mzXML, mzData) into mzXML which MaxQuant will understand. The FileConverter tool has an advanced option called -force_MaxQuant_compatibility, which enforces the "Thermo Scientific" manufacturer and a file index (among other minor things). You should use this flag for all types of data, even for Thermo input data, and then adapt the "Orbitrap" and "ITMS" settings in MaxQuant accordingly.
The commandline call could look like this:
// works for many input types, such as mzML (from OpenMS 2.3 onwards), mzXML (from OpenMS 2.5 onwards), mzData (not really tested) $ FileConverter -force_MaxQuant_compatibility -in my.mzML -out my_MQ.mzXML
For batch processing (on Windows), just create a batch file (.bat) and use a loop:
// put the next line in a batch file and run it by doulbe-clicking. It iterates over all mzML files and converts them to mzXML using OpenMS for %%i in (*.mzML) do echo FileConverter -force_MaxQuant_compatibility -in %%i -out %%i_converted.mzXML
Alternatively, if you prefer a GUI you can use TOPPAS (shipped with OpenMS).
Conversion from mzML to mzXML was tested quite thoroughly since the beginning. If you already have (MQ-incompatible) mzXML as input to FileConverter, you need OpenMS 2.5 or later to generate MQ-compatible mzXML (see https://github.com/OpenMS/OpenMS/pull/4424).
Conclusion
In conclusion, this means:
- You can use ReAdW 4.3.1 as described or a recent development version of OpenMS or later (e.g. OpenMS 2.2 – published about May 2017!) to produce MaxQuant compatible mzXML
- ProteoWizard can be used, but MaxQuant will not produce optimal results (due to wrong msManufacturer setting)
- if the correct msManufacturer is given in the mzXML, MaxQuant assumes FTMS+ITMS data (i.e. Velos, Orbitrap XL, etc)
- if the mzXML gets the msManufacturer wrong, MaxQuant assumes some generic data with more loose MS1 settings (which cannot be modified) and "Unknown" MS/MS settings in MaxQuant GUI (whose parameters indeed have an effect), which leads to drastically fewer peptides and protein IDs – so this should be avoided
- If you are dealing with mzXML's which deviate from FTMS+ITMS (e.g. pure FTMS data from Q-Exactive, or TOF data), then the default MaxQuant settings for FTMS+ITMS are not ideal. Simply adapt the "Orbitrap" and "ITMS" settings in MaxQuant to match your data.
We hope this post was useful and we'd be happy to hear if this worked for your data just as well as it did for ours.
You can leave a reply here or e-mail .
Cheers,
Chris {CoDeMS}
This work was created out of pure curiosity and in our spare time. If you liked it, we'd be happy to accept donations (cookies or others) or enquiries regarding contract work.